OME-NGFF
October 24th 2023
BioImage Town
 cc-by J. Moore et al.
cc-by J. Moore et al.
ZARR: a hierarchical, cloud native format
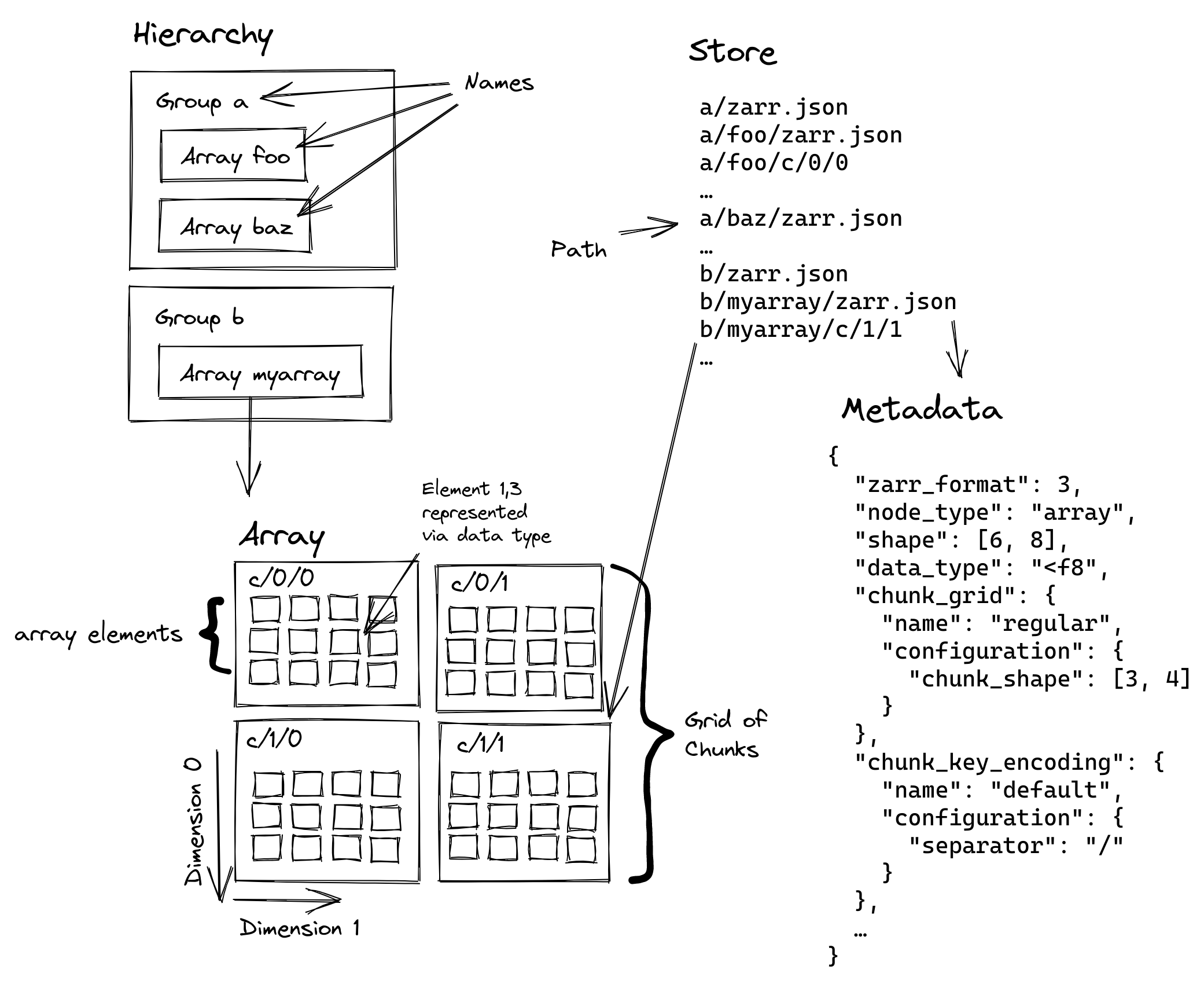
Pyramids and Chunks

- Efficient browsing
- Efficient res-slicing
- Parallel I/O
- Parallel compute
Napari
napari --plugin napari-ome-zarr https://uk1s3.embassy.ebi.ac.uk/idr/zarr/v0.1/4495402.zarr

Fiji and MoBie

Community

